System Design 101: Designing Uber

Let's now put our framework for System Design into practise. I'll try and be as comprehensive for the sake of clarity.
System Overview
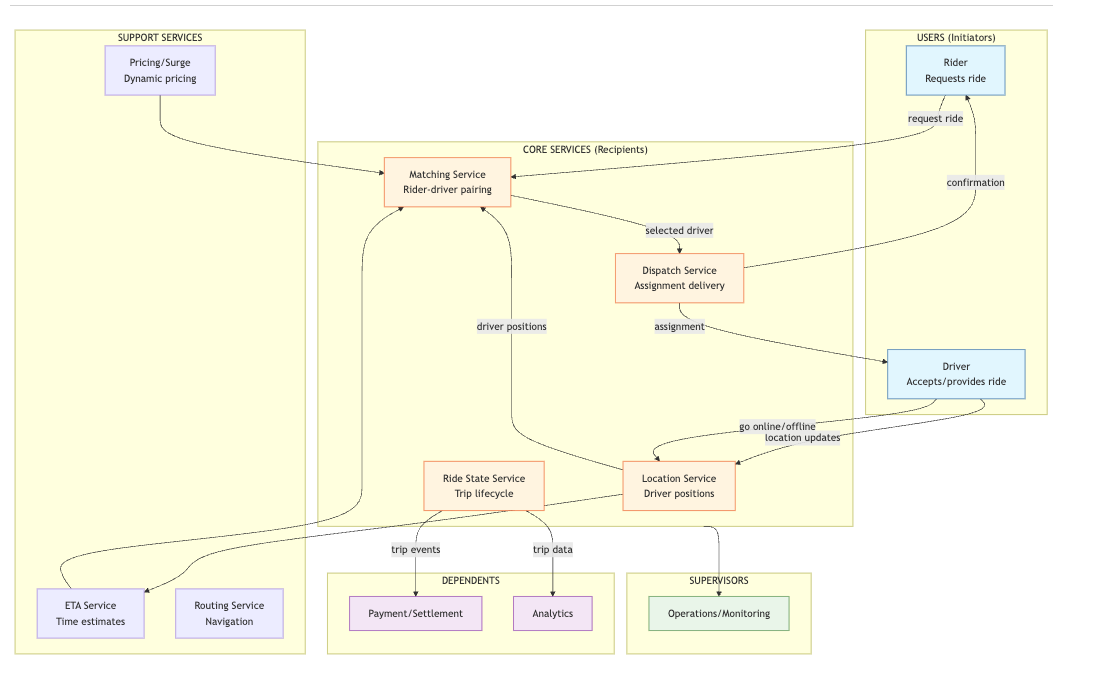
Observers
Rider
Type: Initiator
Time: Acknowledgment latency. How long from requesting until knowing a driver is assigned?
Wrongness tolerance: Cannot tolerate ambiguity—must know yes or no. Cannot tolerate phantom confirmations—told a driver is coming when none is. Can tolerate "no drivers available" as a clear answer. Can tolerate waiting for pickup once they know it's happening.
Pressure contribution: Retries on slow acknowledgment. Parallel requests across competing apps. Geographic and temporal clustering (events, weather, rush hour).
Driver
Type: Initiator (going online) and Recipient (receiving dispatch)
Time: As initiator—how quickly do rides arrive after going online?
As recipient—seconds to decide on a dispatch before it times out or reassigns.
Wrongness tolerance: Cannot tolerate phantom rides—dispatched to a rider who canceled or doesn't exist. Cannot tolerate impossible pickups—wrong location, inaccessible destination. Can tolerate suboptimal matching if volume is steady.
Pressure contribution: Goes offline when demand is low. Rejects marginal rides when demand is high. Availability is the supply constraint.
Location Service
Type: Recipient
Expects: Position updates from active drivers.
Time: Freshness. The gap between a driver's true position and their known position. Updates arrive continuously, but every update is already stale.
Wrongness tolerance: Tolerates small position drift—driver 100 meters from reported location. Cannot tolerate large staleness—driver reported as 2 minutes away who is actually 15 minutes away. Cannot tolerate phantom availability—drivers shown as available who aren't.
Pressure contribution: Geographic concentration spikes update density in one area. High driver count increases processing load. Stale data under load causes cascading bad matches.
Matching Service
Type: Recipient (receives ride requests and location data)
Expects: Accurate location data. Accurate driver availability. Time to compute.
Time: Decision latency vs decision quality. More time means better matches. But rider is waiting. Time is the trade-off between optimal and fast.
Wrongness tolerance: Tolerates suboptimal matches—a slightly farther driver is fine. Cannot tolerate matching to unavailable drivers—triggers dispatch failure. Cannot tolerate matching to phantom drivers—creates rider wrongness.
Pressure contribution: Under load, must decide faster with less information. Many simultaneous requests compete for same drivers. Geographic clustering creates contention.
Dispatch Service
Type: Initiator (to driver) and Recipient (of match result)
Expects: Driver acknowledgment within timeout. Clear accept or reject.
Time: Round-trip acknowledgment. Send dispatch, wait for response, confirm or reassign.
Wrongness tolerance: Cannot tolerate ambiguous acknowledgment—must know if driver accepted. Tolerates rejection—can reassign. Cannot tolerate silent failure—driver never received dispatch but system thinks they did.
Pressure contribution: Timeouts under network congestion. Reassignment cascades when drivers reject or don't respond. Multiple dispatches to same driver across race conditions.
Ride State Service
Type: Recipient (of state transitions) and source of truth for others
Expects: Ordered state transitions: requested → matched → driver en route → arrived → in progress → completed/canceled.
Time: Propagation delay. How long until all parties (rider app, driver app, backend systems) agree on current state?
Wrongness tolerance: Cannot tolerate divergent state—rider sees "driver arriving" while driver sees "canceled." Cannot tolerate impossible transitions—"completed" before "in progress." Tolerates brief propagation delay if eventual consistency is achieved.
Pressure contribution: High event volume during peak. Network partitions between apps and backend. State reconciliation load after outages.
Payment/Settlement
Type: Dependent
Expects: Complete ride records. Stable fare calculations. Consistent history.
Time: Historical. Evaluates hours to weeks after rides complete. Reconciles with credit card processors, driver payments, dispute resolution.
Wrongness tolerance: Cannot tolerate ambiguous rides—did this trip happen or not? Cannot tolerate changing fares—what the rider was charged must match what the driver is paid. Cannot tolerate missing data—gaps in the audit trail.
Pressure contribution: Doesn't create real-time pressure. Surfaces pressure damage later as reconciliation failures, disputes, incorrect payouts.
Operations/Monitoring
Type: Supervisor
Expects: System health signals. Match success rates. Dispatch failure rates. Latency distributions. Geographic coverage.
Time: Detection delay. How long until a problem becomes visible as a pattern?
Wrongness tolerance: Tolerates individual failures—a single bad match is noise. Cannot tolerate invisible degradation—match rates dropping without alerting. Cannot tolerate silent geographic failures—entire city with no available drivers showing green metrics.
Pressure contribution: Interventions during crises can create additional wrongness—restarting services, clearing queues, manual overrides.
Where Wrongness Accumulates
Between Location Service and Matching Service
Location Service holds driver positions. Matching Service queries them. The gap between query and reality is where wrongness lives.
A driver's position update arrives. One second later, Matching queries for drivers near a rider. The driver has moved. The position is already wrong—not by much, but wrong.
Under normal conditions, this wrongness is tolerable. Drivers move slowly relative to query frequency. A few hundred meters of drift doesn't break matching.
Under pressure, this wrongness compounds. Updates arrive slower as volume increases. Matching makes more queries as requests flood in. The gap widens. Drivers shown as 3 minutes away are actually 8 minutes away. Matches degrade. Riders wait longer than promised. Riders cancel and retry. More requests. More pressure.
Between Matching Service and Driver Availability
Matching sees a driver as available. Matching assigns rider to driver. But in the gap between seeing and assigning, the driver:
- Accepted another ride
- Went offline
- Moved out of range
The driver's availability at query time is not their availability at dispatch time. This is a time-of-check to time-of-use gap. Under normal load, it's rare—drivers don't change state that fast, queries don't take that long.
Under pressure, this gap explodes. Many riders request simultaneously. Matching queries the same drivers for multiple requests. Multiple matches target the same driver. Only one can succeed. The rest fail at dispatch.
Failed dispatches create wrongness that flows backward to riders. "We're finding you a driver" was a lie. The match failed. Retry. But now the rider has been waiting. Their tolerance is lower. They're closer to abandoning.
Between Dispatch and Driver Acknowledgment
Dispatch sends assignment to driver. Driver must acknowledge. Three things can go wrong:
Driver never receives dispatch (network failure). System thinks driver was notified. Driver doesn't know they have a ride. Rider waits. Eventually timeout. Wrongness surfaces as delay.
Driver receives dispatch, accepts, but acknowledgment doesn't reach backend. System thinks driver didn't respond. System reassigns to another driver. Original driver heads toward rider. New driver also heads toward rider. Two drivers, one rider. Wrongness surfaces as confusion, wasted driver time, potential conflict.
Driver receives dispatch, rejects (or ignores), but rejection is slow to arrive. System waits for timeout before reassigning. Rider waits. Wrongness surfaces as unnecessary delay.
Under pressure, network gets congested. Timeouts become more common. The ambiguous middle state—dispatch sent, response unknown—expands.
Between Ride State Service and Clients (Rider App, Driver App)
Ride State Service holds the truth. Apps display the state. Propagation takes time. The gap between truth and display is where wrongness lives.
Driver cancels. State Service records cancellation. Rider app hasn't received update. Rider still sees "driver en route." Rider is waiting for a driver who isn't coming.
Rider cancels. State Service records cancellation. Driver app hasn't received update. Driver is driving toward a pickup that doesn't exist.
Under normal conditions, propagation is fast. Gaps are sub-second. Under pressure—network congestion, server load, geographic routing issues—gaps widen. State divergence persists longer. Wrongness becomes visible to users as confusion, wasted time, frustration.
Between Real-time Systems and Payment/Settlement
Rides complete. State transitions are recorded. Fares are calculated. Later, Payment needs to reconcile.
If state transitions were inconsistent—multiple "completed" events, missing "started" events, timestamps that don't make sense—Payment inherits wrongness it cannot resolve.
If surge pricing changed mid-ride but the record doesn't capture which rate applied when, Payment cannot calculate correctly. Driver disputes the payout. Rider disputes the charge.
This wrongness was created in real-time under pressure. It surfaces days or weeks later when Settlement runs. The real-time systems have moved on. The context that might explain the wrongness is gone.
What Happens Under Pressure
Pressure source: Thousands of ride requests in the same geographic area within minutes. Concert ends. Game finishes. New Year's Eve. Rainstorm starts.
Rider time horizon compresses.
They expected acknowledgment in 5-10 seconds. At 15 seconds, they're anxious. At 30 seconds, they retry or switch apps.
Under normal load, 5-10 seconds is achievable. Under pressure, matching takes longer (more requests competing for fewer drivers), dispatch takes longer (network congestion), acknowledgment takes longer.
Riders don't adjust their expectations because load is high. Their threshold stays fixed. System performance degrades. The gap between expectation and reality widens. Retries increase. Each retry adds load. Pressure amplifies.
Location freshness degrades.
Update frequency stays constant (drivers still send updates), but processing slows. Queries return older positions. Matches are based on stale data.
Staleness creates bad matches. Bad matches create longer pickups. Longer pickups increase ride duration. Drivers are occupied longer. Supply decreases further. Pressure amplifies.
Matching contention increases.
Same drivers appear in multiple simultaneous queries. Multiple matches target same driver. Only first dispatch succeeds. Others fail.
Failed matches need reassignment. Reassignment takes time. Riders wait. Waiting riders retry or cancel. Cancellations need cleanup. Retries add load. Pressure amplifies.
Dispatch reliability drops.
Network congestion increases packet loss. Dispatch timeouts increase. Ambiguous states multiply—did driver receive dispatch or not?
Conservative response: wait for timeout before reassigning. Cost: rider waits longer. Aggressive response: reassign quickly on no response. Cost: duplicate dispatches, phantom rides.
Neither choice removes wrongness. Both route it differently.
State propagation lags.
Backend updates faster than apps can sync. State divergence windows widen. Riders and drivers see different realities for longer periods.
Driver cancels, rider doesn't know. Rider cancels, driver doesn't know. Both waste time. Both experience the system as broken.
Operations visibility degrades.
Metrics lag behind reality. Dashboards show state from 30 seconds ago. By the time supervisors see the problem, it has compounded.
Interventions based on stale data may be wrong. Scaling up capacity that's already scaled. Throttling traffic that's already throttled. Actions that made sense 30 seconds ago create new wrongness now.
Constraints and Questions
From this analysis, what must the design answer?
Location Service:
- How stale is too stale?
- How do we bound staleness under load?
- Do we degrade update frequency gracefully, or maintain frequency and drop updates?
Matching Service:
- How do we prevent multiple matches to the same driver?
- How do we balance match speed vs match quality?
- Do we reserve drivers during matching, or match optimistically and handle conflicts at dispatch?
Dispatch Service:
- How long do we wait for driver acknowledgment before reassigning?
- How do we distinguish "driver didn't receive" from "driver is deciding"?
- How do we prevent duplicate dispatches?
Ride State Service:
- How do we propagate state changes fast enough to prevent divergence?
- Who is the source of truth when rider app and driver app disagree?
- How do we handle state changes that arrive out of order?
Rider Experience:
- What do we show during matching? Honest uncertainty or reassuring progress?
- When do we tell the rider no drivers are available vs keep trying?
- How do we prevent retry storms?
Driver Experience:
- How do we prevent phantom dispatches?
- How do we ensure driver's accept/reject is always recorded?
- How do we prevent two-drivers-one-rider scenarios?
Payment/Settlement:
- What ride data must be immutable from the moment of capture?
- How do we ensure fare calculation is deterministic and reproducible?
- How do we handle disputes when real-time state was ambiguous?
Candidate Designs
Location Service
The problem: Know where drivers are, right now. But "right now" doesn't exist—every update is already stale.
Simplest design: Drivers send GPS coordinates. Service stores latest position per driver. Queries return stored position.
Where wrongness accumulates: The gap between stored position and true position. Driver moving at 30 mph travels 44 feet per second. A 5-second-old update is 220 feet wrong. Acceptable. A 30-second-old update is 1,320 feet wrong. Possibly not acceptable.
Design choice 1: Update frequency
High frequency (every 1-2 seconds):
- Freshness improves
- Battery drain increases on driver phones
- Network and storage load increases
- Under pressure, processing may not keep up—updates queue, staleness increases anyway
Low frequency (every 10-15 seconds):
- Battery and network load manageable
- Staleness is higher but bounded
- Under pressure, system handles load better—but data is less fresh even in normal conditions
Tradeoff: High frequency privileges Matching (fresher data for better matches) and taxes Drivers (battery) and infrastructure (load). Low frequency privileges infrastructure stability and taxes match quality.
Design choice 2: What happens under load?
Option A: Accept all updates, let processing queue grow.
- Staleness increases under pressure
- Wrongness grows silently—Matching doesn't know data is stale
- Pressure converts to wrongness for downstream systems
Option B: Drop updates when queue exceeds threshold.
- Staleness is bounded—last known position may be old, but system isn't pretending it's fresh
- Some drivers become invisible temporarily
- Wrongness is visible—Matching knows some positions are missing
Option C: Degrade to coarser updates (position buckets instead of exact coordinates).
- Reduces processing load
- Matching works with less precision but fresher data
- Wrongness is transformed—less precise but more current
Tradeoff: Option A hides wrongness until it compounds. Option B surfaces wrongness immediately (missing drivers). Option C transforms wrongness (imprecision instead of staleness). No option eliminates wrongness.
Design choice 3: How does Matching know position age?
Option A: Return position only.
- Matching assumes freshness
- Staleness is invisible
- Bad matches happen without explanation
Option B: Return position with timestamp.
- Matching can decide how to use stale data
- Complexity moves to Matching
- Staleness is visible, not hidden
Tradeoff: Option A is simpler but routes wrongness silently to riders (bad matches). Option B exposes wrongness to Matching, which can make informed decisions.
Design synthesis for Location Service:
- Update frequency: adaptive. Normal conditions every 3-5 seconds. Under pressure, accept degradation to 10-15 seconds.
- Under load: drop oldest updates in queue, not newest. Better to have fewer fresh positions than many stale ones.
- Always return timestamp with position. Let Matching decide what to do with stale data.
- Surface staleness, don't hide it. A visible gap is better than an invisible bad match.
Matching Service
The problem: Given a ride request, find a driver. Quickly. But quickly and optimally conflict.
Simplest design: Query Location for nearby drivers. Sort by distance. Assign closest available driver.
Where wrongness accumulates:
Between "nearby drivers" and "available drivers." Location knows position. Who knows availability? The driver's state—online, on a ride, en route to pickup—lives elsewhere. Matching must join position data with availability data. The join is a moment in time. Reality has already moved.
Between "assign" and "accept." Matching picks a driver. That driver doesn't know yet. Until they accept, the match is provisional. But the rider is waiting.
Design choice 1: What does "assign" mean?
Option A: Assign means "we've picked this driver, pending their acceptance."
- Honest to rider: "finding you a driver"
- If driver rejects, try again
- Rider experiences uncertainty for longer
- No false promises
Option B: Assign means "you're matched"—tell rider immediately, then dispatch.
- Rider gets fast acknowledgment
- If driver rejects, rider experiences a reversal—"driver coming" then "finding new driver"
- Fast but potentially wrong
Tradeoff: Option A keeps wrongness in the system (rider sees uncertainty). Option B moves wrongness to rider (reversal if dispatch fails). Option A is honest but slow. Option B is fast but may lie.
Design choice 2: How do we prevent multiple matches to the same driver?
Option A: Optimistic matching. Query, match, dispatch. Handle conflicts at dispatch.
- Fast—no coordination during matching
- Under pressure, many requests target same drivers
- Dispatch failures increase
- Wrongness surfaces as failed dispatches and reassignment delays
Option B: Pessimistic matching. Reserve driver atomically before confirming match.
- Slower—requires coordination
- No double-matching
- Under pressure, reservation contention becomes bottleneck
- Wrongness surfaces as matching latency
Option C: Partition by geography. Each partition matches independently for its area.
- No global coordination
- Drivers near partition boundaries may be invisible to requests just across the line
- Wrongness surfaces as suboptimal matches at boundaries
Tradeoff: Optimistic privileges speed, pays at dispatch. Pessimistic privileges consistency, pays at matching. Partitioning privileges scale, pays at boundaries.
Design choice 3: How long to search for optimal vs return fast?
Option A: First acceptable match wins.
- Fastest response
- Match quality is "good enough"
- Under pressure, degrades gracefully—same algorithm, just fewer options
Option B: Search for N seconds or until K candidates, pick best.
- Better matches in normal conditions
- Under pressure, N seconds feels long, K candidates may not exist
- Must decide: fail fast or wait hopefully?
Tradeoff: Option A always returns quickly, quality is variable. Option B returns better matches when available, but under pressure may wait for quality that doesn't exist.
Design synthesis for Matching Service:
- Use timestamps from Location. Discount or exclude drivers with stale positions.
- Reserve driver atomically before confirming match. Accept matching latency to prevent dispatch failures.
- Tell rider "finding driver" until dispatch is acknowledged. Don't promise what isn't confirmed.
- Under pressure, shrink search radius and accept first viable match. Speed matters more than optimality when supply is scarce.
- Surface match quality metrics to Operations. Let supervisors see when matches degrade.
Dispatch Service
The problem: Notify driver of assignment. Get acknowledgment. Confirm to rider. Three parties must reach mutual awareness.
Simplest design: Send push notification to driver. Wait for response. On accept, notify rider. On reject or timeout, return to Matching for reassignment.
Where wrongness accumulates:
The three-way coordination. Backend knows it sent dispatch. Did driver receive it? Driver knows they accepted. Did backend receive acceptance? Backend confirmed to rider. Did rider receive confirmation?
Each link can fail. Each failure creates a different wrongness.
Design choice 1: How long to wait for driver response?
Short timeout (5-10 seconds):
- Rider waits less before reassignment
- Driver has less time to decide
- Drivers in poor network conditions timeout unfairly
- Reassignment cascades are faster
Long timeout (20-30 seconds):
- Driver has time to see dispatch, understand pickup location, decide
- Rider waits longer before reassignment
- Under pressure, long timeouts compound delay
Tradeoff: Short timeout privileges rider time, taxes drivers (less decision time) and creates more reassignments. Long timeout privileges drivers, taxes riders.
Design choice 2: What if acknowledgment is lost?
Driver accepts. Network drops the acceptance. Backend times out. Backend reassigns to new driver.
Option A: No mitigation. Driver arrives at pickup, finds different driver there. Wrongness surfaces as confusion.
Option B: Driver-side timeout. If driver doesn't see "rider confirmed" within N seconds of accepting, show "dispatch may have failed." Driver can re-confirm or move on.
- Requires driver to take action
- Reduces phantom ride frequency
- Adds driver cognitive load
Option C: Backend retries dispatch confirmation to driver. If driver already accepted, driver receives "confirmed" again (idempotent). If driver never received dispatch, they receive it now.
- More network traffic
- Handles transient failures
- Doesn't help if driver's network is persistently bad
Tradeoff: Option A hides wrongness until it becomes visible conflict. Option B surfaces wrongness to driver, asks them to act. Option C tries to resolve wrongness automatically but adds complexity.
Design choice 3: How do we prevent two-drivers-one-rider?
This happens when:
- Dispatch sent to Driver A, times out
- Dispatch sent to Driver B, succeeds
- Driver A's delayed acceptance arrives
Option A: Accept first, reject subsequent. Backend records which driver is assigned. Late acceptances are rejected with "ride already assigned."
- Clean resolution
- Requires Driver A to handle rejection gracefully
- Driver A wasted time driving toward pickup
Option B: Idempotency token. Each dispatch has unique ID. Only acceptance with matching ID is valid.
- Late acceptance with old ID is automatically invalid
- No race condition at backend
- Driver still wasted time
Neither option prevents Driver A from starting to drive before their acceptance is confirmed. The wrongness is in the time gap between dispatch and confirmation.
Tradeoff: Both options resolve the backend state correctly. Neither solves the real-world wrongness of a driver wasting time. Only shorter timeouts reduce that waste, but shorter timeouts create other problems.
Design synthesis for Dispatch Service:
- Moderate timeout (10-15 seconds). Balance between rider wait time and driver decision time.
- Idempotency tokens on all dispatches. Late responses automatically invalid.
- Driver-side confirmation screen. Show "waiting for confirmation" after accepting, resolve to "rider confirmed" or "ride reassigned."
- Backend retries confirmation to driver once on success, to handle transient network failure.
- Log dispatch lifecycle fully. When wrongness surfaces later (complaints, disputes), the record must show what happened.
Ride State Service
The problem: Single source of truth for ride lifecycle. Rider app, driver app, backend systems all depend on this state.
States: Requested → Matched → Driver En Route → Driver Arrived → Ride In Progress → Completed / Canceled
Simplest design: State machine with transitions. Each transition is an event. Latest state is queryable. Apps poll or subscribe for updates.
Where wrongness accumulates:
Propagation delay. State changes in backend. Apps learn later. The gap between truth and display is where wrongness lives.
Out-of-order events. Under network partition, events arrive at apps in different orders. Rider app sees "arrived" then "en route." Which is true?
Conflicting transitions. Rider cancels while driver is arriving. Driver completes ride while rider is disputing. Who wins?
Design choice 1: How do apps learn about state changes?
Option A: Polling. Apps query current state every N seconds.
- Simple
- Stale between polls
- Under pressure, polling load adds to system strain
Option B: Push via persistent connection (WebSocket, long-poll).
- Near-real-time updates
- Connection management complexity
- Under pressure, connections may drop, reconnection storms
Option C: Push with polling fallback. Push for real-time, poll to recover from missed pushes.
- Best of both
- More complex
- Must handle push and poll returning different states during propagation
Tradeoff: Polling is simple but stale. Push is current but complex. Combination handles failures but must reconcile inconsistency.
Design choice 2: Who can transition state?
Option A: Only backend, based on events from apps.
- Single source of truth
- Apps must report events, backend must be reachable
- Under network partition, state can't advance
Option B: Apps can transition locally, sync later.
- Works offline
- Conflict resolution required when syncs arrive
- Multiple sources of truth during partition
Tradeoff: Centralized truth is consistent but requires connectivity. Distributed truth works offline but creates reconciliation complexity.
Design choice 3: How do we handle conflicting transitions?
Rider cancels at T1. Driver completes at T2. Both events arrive at backend at T3. Which wins?
Option A: Timestamp wins. Earlier event takes precedence.
- Requires synchronized clocks (difficult on mobile)
- Spoofable
Option B: First-to-arrive wins.
- Network latency determines outcome
- Feels arbitrary
Option C: State-specific rules. Some states block certain transitions. "In Progress" cannot be canceled by rider—only completed or disputed. "En Route" can be canceled by either party.
- Business logic determines validity
- Clear rules, predictable outcomes
- Some valid scenarios may be blocked
Tradeoff: Time-based is "fair" but technically problematic. Arrival-based is simple but arbitrary. Rule-based is principled but rigid.
Design synthesis for Ride State Service:
- Persistent connections for primary updates, polling for recovery.
- Backend is single source of truth. Apps report events, backend transitions state.
- State-specific transition rules. Model the business logic explicitly. Document what transitions are valid from each state.
- Include sequence numbers with state. Apps can detect missed states, request fill.
- Log all transition attempts, including rejected ones. Disputes require knowing what was attempted, not just what succeeded.
Payment/Settlement
The problem: Charge rider correctly. Pay driver correctly. Reconcile with external payment processors. Handle disputes.
This is a dependent. It evaluates historical truth.
Simplest design: On ride completion, calculate fare based on recorded route, time, surge multiplier. Charge rider. Credit driver. Store record.
Where wrongness arrives:
Ambiguous completion. Did the ride complete? State shows "completed" but rider disputes they ever got in the car.
Inconsistent inputs. Route recorded shows 5 miles. Rider's app shows 3 miles. Which is true?
Retroactive changes. Support edited the ride record to address a complaint. Settlement already ran. Driver payout was based on old record.
Surge ambiguity. Surge was 2.5x when ride was requested. By pickup, surge was 1.5x. Which applies?
Design choice 1: When is fare calculated?
Option A: At completion. Use final recorded values.
- Simple
- If recording was wrong during ride, wrongness is baked in
- No recourse for rider until dispute
Option B: At request, estimated. At completion, reconciled.
- Rider sees estimate upfront
- Variance between estimate and actual creates disputes
- Must decide: honor estimate or charge actual?
Tradeoff: Calculate-at-end is simple but surprises riders. Estimate-and-reconcile is transparent but creates expectation gaps.
Design choice 2: What is immutable?
Option A: Everything is mutable. Support can fix any field.
- Maximum flexibility
- No stable history
- Reconciliation is impossible if records change after the fact
Option B: Core fields are immutable. Corrections are separate events.
- Audit trail preserved
- Original wrongness and correction both visible
- More complex data model
Tradeoff: Mutable records are operationally flexible but destroy trust for dependents (reconciliation, auditing). Immutable core with correction events preserves history but adds complexity.
Design choice 3: How do we handle disputes?
Rider says: "I was charged $50 but the ride was only 10 minutes." Driver says: "Traffic was terrible, ride took 40 minutes." Record shows: 38 minutes, $50 fare.
Option A: Record wins. Automated resolution.
- Scalable
- No human judgment
- Wrong records create wrong outcomes
Option B: Human review with full event log.
- Can assess context
- Expensive
- Slow
Option C: Tiered. Small disputes automated. Large disputes reviewed.
- Balances cost and fairness
- Must define thresholds
- Gaming possible around thresholds
Tradeoff: Automation scales but propagates wrongness. Human review is accurate but expensive. Tiering balances but creates threshold artifacts.
Design synthesis for Payment/Settlement:
- Calculate estimate at request time using current surge, expected route. This is the rider's contract.
- At completion, calculate actual. If actual exceeds estimate by more than threshold, cap at estimate plus tolerance. Rider's expectation is bounded.
- Core ride data is append-only. Original values preserved. Corrections are new events referencing originals.
- Reconciliation runs against immutable log. Can always reproduce how a number was calculated.
- Disputes have full event trail. Every state transition, every correction, every calculation input is logged.
Operations/Monitoring
The problem: See system health. Detect problems before they cascade. Intervene effectively.
This is a supervisor. Detection time is their constraint.
Simplest design: Aggregate metrics (request rate, match rate, dispatch success rate, average ETA). Alert when metrics cross thresholds. Dashboard for humans.
Where wrongness hides:
Aggregate masks local. Global match rate is 95%. But match rate in downtown during the concert is 40%. Aggregate looks fine.
Lag hides current state. Metrics are 30 seconds old. Incident started 45 seconds ago. Dashboard shows "healthy."
Success metrics hide experience. "Match rate 95%" doesn't reveal that matched rides have 20-minute ETAs because all close drivers are occupied.
Design choice 1: What granularity of metrics?
Option A: Global aggregates only.
- Simple
- Local failures invisible
- Under pressure, problems are hidden until they're global
Option B: Geographic and temporal slicing.
- Can see "downtown, last 5 minutes"
- Many more metrics
- Alert fatigue risk
- Requires knowing where to look
Tradeoff: Global is simple but blind to local. Sliced is comprehensive but overwhelming.
Design choice 2: How fast must metrics update?
Option A: Batch aggregation (every 1-5 minutes).
- Efficient
- Detection delay is 1-5 minutes plus pattern recognition time
- Incidents compound before visibility
Option B: Streaming aggregation (seconds).
- Near real-time visibility
- Infrastructure cost
- Must filter noise from signal in raw stream
Tradeoff: Batch is efficient but late. Streaming is current but noisy and expensive.
Design choice 3: What triggers alerts vs requires human judgment?
Option A: Fixed thresholds. Match rate < 90% = alert.
- Simple
- Doesn't account for context (expected load, time of day)
- False positives during anticipated peaks
Option B: Anomaly detection. Alert when metrics deviate from predicted baseline.
- Context-aware
- Requires accurate baseline
- May miss slow degradation within "normal" variance
Tradeoff: Fixed thresholds are predictable but context-blind. Anomaly detection is adaptive but requires tuning and may miss gradual drift.
Design synthesis for Operations/Monitoring:
- Slice metrics by geography and time. Global aggregates for overview, ability to drill down.
- Streaming aggregation for critical metrics (match rate, dispatch success). Batch for analysis metrics.
- Alert on both absolute thresholds and rate of change. Match rate < 80% alerts. Match rate dropping 10% in 5 minutes alerts regardless of absolute level.
- Surface rider and driver experience metrics, not just system success metrics. ETA distribution matters as much as match rate.
- Intervention playbook. When alert fires, what actions are available? What wrongness does each action create?
Summary of Design Tradeoffs
| System | Primary Tradeoff | Who Gains | Who Pays |
|---|---|---|---|
| Location | Freshness vs load | Matching (fresher data) vs Infrastructure (load) | Matching pays when staleness hidden; infrastructure pays when freshness demanded |
| Matching | Speed vs optimality | Rider (fast response) vs Rider (better match) | Fast + suboptimal or slow + optimal; under pressure, fast wins |
| Matching | Optimistic vs pessimistic assignment | Speed (optimistic) vs Consistency (pessimistic) | Optimistic pays at dispatch; pessimistic pays at matching |
| Dispatch | Timeout length | Rider (short) vs Driver (long) | Short = more reassignments; long = more waiting |
| Ride State | Push vs poll | Currency (push) vs Simplicity (poll) | Push complexity; poll staleness |
| Ride State | Centralized vs distributed truth | Consistency (central) vs Availability (distributed) | Central needs connectivity; distributed needs reconciliation |
| Payment | Mutable vs immutable records | Operations (mutable) vs Audit (immutable) | Mutable destroys history; immutable adds complexity |
| Operations | Aggregate vs sliced metrics | Simplicity (aggregate) vs Visibility (sliced) | Aggregate hides local failures; sliced overwhelms |
Each design choice routes wrongness somewhere. The system works when wrongness routes to observers who can tolerate it. The system fails when pressure compresses time, wrongness accumulates faster than tolerance allows, and multiple observers exceed their limits simultaneously.