Software Design 101: Twitter Timeline

System Overview
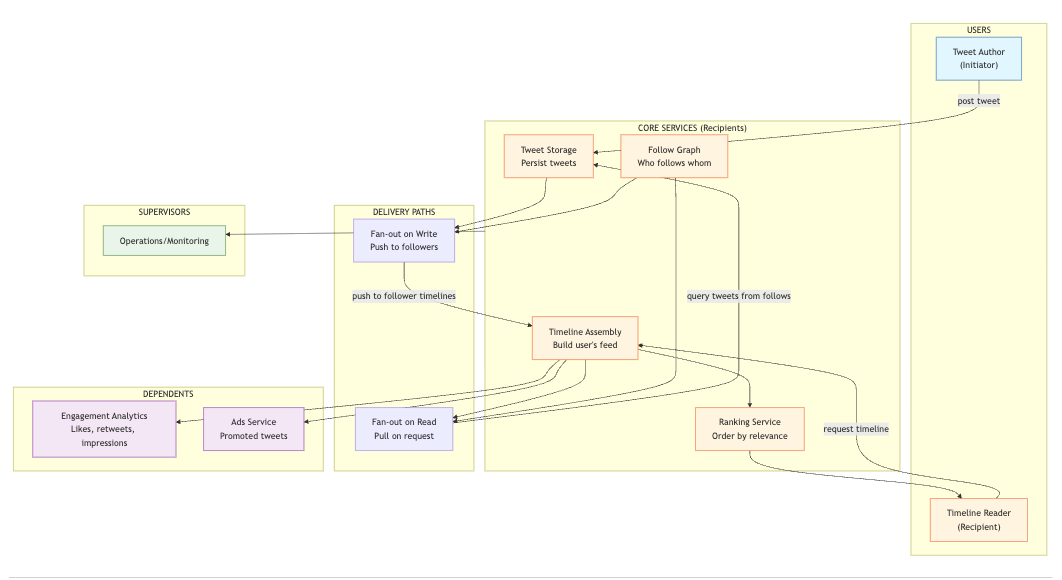
Observer Analysis
Tweet Author (Initiator)
Type: Initiator
Time: How long from posting until they know the tweet exists? Then, distribution latency. How long until followers can see it?
Wrongness tolerance: Cannot tolerate lost tweets—posted but never persisted. Cannot tolerate ambiguity—did it post or not? Can tolerate distribution delay if the tweet is eventually visible. Can tolerate not everyone seeing it immediately.
Pressure contribution: Posting velocity is usually manageable. Pressure comes from high-profile moments—breaking news, live events—when many authors post simultaneously about the same thing.
Timeline Reader (Recipient)
Type: Recipient
Time: Freshness. When I open the app, how recent are the tweets I see? Am I seeing what's happening now, or what happened an hour ago?
Wrongness tolerance: Can tolerate some staleness—minutes-old tweets are fine. Can tolerate missing some tweets—no one expects to see every tweet from every follow. Cannot tolerate gross staleness—seeing yesterday's tweets when news is breaking now. Cannot tolerate incoherence—seeing a reply without the original, seeing tweets badly out of order.
Pressure contribution: Read load is highly variable. Spikes during major events, sports, breaking news. Millions of users refreshing simultaneously.
Follow Graph Service (Recipient)
Type: Recipient of follow/unfollow events, queried by other services
Expects: Accurate follower lists. When asked "who follows user X?" or "who does user Y follow?", returns correct answer.
Time: Propagation delay. User follows someone new. How long until that relationship is reflected in timeline assembly?
Wrongness tolerance: Tolerates brief inconsistency—follow just happened, not reflected yet. Cannot tolerate persistent wrongness—followed someone a day ago, still not seeing their tweets. Cannot tolerate phantom relationships—unfollowed someone, still seeing their tweets.
Pressure contribution: Relatively stable. Follows/unfollows are less frequent than reads or posts. Pressure comes from queries during timeline assembly at scale.
Tweet Storage (Recipient)
Type: Recipient of new tweets
Expects: Tweets arrive, must be persisted durably.
Time: Write latency. How long from receiving tweet until confirmed durable?
Wrongness tolerance: Cannot tolerate data loss—tweet accepted but not persisted. Tolerates brief unavailability for reads if writes are safe.
Pressure contribution: Write volume during peak events. Read volume when timelines are assembled via fan-out-on-read.
Timeline Assembly (could be a service or a pattern)
This is where the core architectural choice lives. Two fundamental approaches:
Fan-out-on-write: When a tweet is posted, push it to all followers' timelines immediately. Timeline read is simple—just fetch pre-assembled list.
Fan-out-on-read: When a user requests their timeline, fetch tweets from all accounts they follow and assemble in real-time.
These are different systems with different observer relationships. Let me characterize both.
Fan-out-on-write model:
Timeline Cache (Recipient of fan-out)
Expects: Receives tweets to add to specific users' timelines.
Time: Ingestion rate. How fast can it absorb fan-out writes?
Wrongness tolerance: Can tolerate brief delays in receiving tweets. Cannot tolerate lost writes—tweet was supposed to be fanned out but wasn't. Cannot tolerate wrong routing—tweet appears in timeline of non-follower.
Pressure contribution: Celebrity posts create massive write amplification. One tweet to 50 million followers = 50 million writes.
Fan-out-on-read model:
Timeline Assembly Service (Recipient)
Expects: On request, fetches tweets from followed accounts, merges, ranks, returns.
Time: Assembly latency. How long from request until timeline is ready?
Wrongness tolerance: Tolerates incomplete results under pressure—return what you have. Cannot tolerate excessive latency—user waiting for timeline to load. Cannot tolerate gross incoherence—badly ordered results.
Pressure contribution: Every timeline request triggers assembly. Read load directly creates assembly load.
Ranking/Relevance Service (Recipient)
Type: Receives candidate tweets, returns ranked order
Expects: Set of tweets, user context. Must score and order.
Time: Ranking latency. Adds to timeline assembly time.
Wrongness tolerance: Tolerates imperfect ranking—suboptimal order is acceptable. Cannot tolerate extreme latency—ranking that takes seconds defeats the purpose.
Pressure contribution: Called for every timeline request. Compute-intensive. Must degrade gracefully.
Engagement/Analytics (Dependent)
Type: Dependent
Expects: Accurate counts—impressions, likes, retweets, replies. Consistent historical data.
Time: Historical. Computes metrics hours or days after events.
Wrongness tolerance: Tolerates approximate real-time counts—showing "10K likes" when it's actually 10,234 is fine. Cannot tolerate major inaccuracy in settled counts—advertiser paying for impressions needs real numbers. Cannot tolerate retroactive changes without explanation.
Pressure contribution: Doesn't create real-time pressure. Inherits wrongness from real-time systems as data inconsistency.
Ads Service (Dependent)
Type: Dependent on impressions, engagement, user attention
Expects: Accurate targeting. Accurate billing. Tweets appear in timelines as promised.
Time: Near-real-time for delivery, historical for billing.
Wrongness tolerance: Cannot tolerate ads shown but not recorded—lost revenue. Cannot tolerate ads recorded but not shown—billing for phantom impressions. Tolerates targeting imprecision within bounds.
Pressure contribution: Adds tweets to timeline assembly. Competes for attention with organic tweets.
Operations/Monitoring (Supervisor)
Type: Supervisor
Expects: System health metrics. Timeline assembly latency. Fan-out lag. Error rates.
Time: Detection delay.
Wrongness tolerance: Tolerates individual failures. Cannot tolerate invisible degradation—timelines getting stale without alerting.
Pressure contribution: Interventions during incidents.
Where Wrongness Accumulates
In the fan-out path (fan-out-on-write)
Author posts tweet. System must write to every follower's timeline. For a user with 1,000 followers, that's 1,000 writes. For a celebrity with 50 million followers, that's 50 million writes.
Wrongness accumulates in the lag between posting and fan-out completion. The author sees their tweet immediately. Follower A sees it in 100ms. Follower Z sees it in 30 seconds. Follower who follows many celebrities may experience significant lag as their timeline queue backs up.
Under pressure—celebrity posts during major event when many celebrities are posting—fan-out queues grow. The gap between "posted" and "visible to all followers" widens.
The celebrity problem: fan-out-on-write is O(followers) per tweet. When followers number in millions, this doesn't scale. Write amplification overwhelms the system.
In the assembly path (fan-out-on-read)
Reader requests timeline. System must query tweets from all followed accounts, merge, rank, return.
For a user following 100 accounts, that's 100 queries (or some optimized batch). For a user following 5,000 accounts, the query load multiplies.
Wrongness accumulates in assembly latency. User is waiting. Each additional followed account adds latency. Ranking adds latency. Under pressure, these latencies compound.
The heavy-reader problem: fan-out-on-read is O(following) per request. When following count is high and request rate is high, query load explodes.
Between Follow Graph and Timeline
User follows a new account. Follow Graph is updated. But:
In fan-out-on-write: new tweets from that account won't appear until next tweet is posted and fanned out. Historical tweets from the new follow don't backfill automatically.
In fan-out-on-read: the follow change is reflected on next timeline request. But if Follow Graph propagation is slow, the new follow may not be queried.
Unfollow is worse. User unfollows. In fan-out-on-write, tweets already in their timeline remain. In fan-out-on-read, next query excludes that account—but cached results may still show them.
Between Ranking and Reader expectation
Reader expects chronological recency. Or do they? Twitter has oscillated between chronological and algorithmic timelines.
If ranking optimizes for engagement, reader may see older "engaging" tweets above newer less-engaging ones. Reader refreshes but sees same tweets. "Why am I not seeing new tweets?"
Ranking creates expectation mismatch. The system believes it's showing the "best" timeline. The reader believes they're missing things.
Between real-time and Analytics/Ads
Impression recorded when tweet enters timeline. But did user actually see it? Timeline assembled, user scrolls past without looking, closes app. Was that an impression?
Engagement counts are approximate in real-time, precise in batch. The gap creates wrongness for advertisers comparing real-time dashboards to invoices.
Ads delivered but not recorded (system under pressure, logging dropped) creates billing wrongness that surfaces later.
What Happens Under Pressure
Pressure source: Major events. World Cup final. Election night. Breaking news. Celebrity death. Millions of users posting and reading simultaneously.
Fan-out-on-write under pressure:
Celebrity tweets. Fan-out begins. 50 million writes to queue.
Before those complete, another celebrity tweets. Another 50 million writes.
Breaking news means many high-follower accounts tweet in short window. Write queues explode. Fan-out lag grows from seconds to minutes.
Readers see stale timelines. "Why isn't the breaking news showing?" They refresh. Refresh triggers read, but timeline cache hasn't received fan-out yet. Still stale.
Readers don't know the system is behind. They see old tweets and assume the system is broken—or worse, assume nothing is happening.
Meanwhile, normal users with small follower counts have their tweets fanned out quickly. Timeline becomes unbalanced—you see your friend's lunch tweet but not the news from accounts you follow.
Fan-out-on-read under pressure:
Reader requests timeline. Assembly service queries tweet storage for all followed accounts.
Millions of readers make simultaneous requests. Each request triggers hundreds of queries. Query load on tweet storage explodes.
Tweet storage slows. Assembly latency increases. Readers wait. Readers retry. Retries add load. Feedback loop.
Ranking service is called for every assembly. Compute-bound. Under pressure, ranking adds latency. If ranking times out, what do we return? Unranked results? Partial results? Empty timeline?
The hybrid model under pressure:
Most systems use hybrid: fan-out-on-write for normal users, fan-out-on-read for celebrities.
Under pressure, this creates edge cases. Which accounts are "celebrities"? Threshold is arbitrary. Account just under threshold gets full fan-out. Account just over doesn't.
When many mid-tier accounts (1M followers) all tweet during an event, none are celebrities by threshold, all trigger fan-out. Combined, they overwhelm the fan-out system even though individually they're "normal."
Follow Graph under pressure:
User follows breaking news account because everyone is talking about it. Many users follow simultaneously.
Follow Graph receives write spike. Propagation lags. New followers don't see tweets from the account they just followed—because the follow hasn't propagated to timeline assembly.
"I just followed them, why don't I see their tweets?"
Analytics under pressure:
Logging systems receive massive event volume. Write paths back up. Logs are dropped or delayed.
Engagement counts become inaccurate. Real-time dashboards show stale data. Advertisers see impression counts that don't move during peak attention.
When pressure passes, reconciliation runs. Counts adjust. "Why did my tweet's impressions jump by 100K an hour after the event?"
Constraints and Questions
Core architectural question:
Fan-out-on-write vs fan-out-on-read is fundamentally a question of where to put the work.
Fan-out-on-write: work happens at write time. Scales writes with follower count. Reads are cheap.
Fan-out-on-read: work happens at read time. Writes are cheap. Scales reads with following count.
Neither eliminates work. Both route pressure differently.
From observer analysis:
Tweet Author:
- How quickly must we acknowledge the tweet?
- How quickly must it be visible to at least some followers?
- What do we show the author about distribution status?
Timeline Reader:
- How fresh must the timeline be?
- What's acceptable latency for timeline load?
- When we can't assemble a complete timeline, what do we show?
- Do we show chronological or ranked order? Who decides?
Follow Graph:
- How quickly must follow changes be reflected?
- How do we handle rapid follow/unfollow (spam, gaming)?
- What consistency guarantee do we provide?
Timeline Assembly:
- How do we handle the celebrity problem?
- How do we bound assembly latency?
- What's the degradation strategy when systems are slow?
Ranking:
- Is ranking required or optional?
- Can we fall back to chronological when ranking is overloaded?
- How do we balance relevance vs recency?
Analytics/Ads:
- What accuracy do we guarantee for real-time counts?
- How do we handle logged events under pressure?
- What's the reconciliation window?
Operations:
- How do we detect timeline staleness?
- How do we detect fan-out lag?
- What interventions are available during overload?
Design Candidates
Tweet Storage
The problem: Persist tweets durably. Serve reads for timeline assembly.
Simplest design: Write tweet to database. Index by author and timestamp. Query by author ID to retrieve recent tweets.
Where wrongness accumulates:
Between write acknowledgment and durability. Author sees "tweet posted." Is it actually persisted? If acknowledgment precedes durable write, a crash loses the tweet.
Between storage and availability for reads. Tweet is persisted. Replica hasn't received it yet. Fan-out-on-read queries replica. Tweet is missing from timeline.
Design choice 1: When do we acknowledge to author?
Option A: Acknowledge after durable write.
- Author knows tweet is safe
- Latency includes disk/replication time
- Under pressure, acknowledgment slows
Option B: Acknowledge after memory write, persist asynchronously.
- Fast acknowledgment
- Crash window where tweet can be lost
- Author believes tweet exists when it might not
Tradeoff: Option A privileges author certainty, taxes latency. Option B privileges speed, taxes durability. Lost tweets are catastrophic for author trust.
Design choice 2: How do we partition tweets?
Option A: By author ID.
- All tweets from one author on same partition
- Author's timeline queries hit one partition
- Hot authors (celebrities) create hot partitions
Option B: By tweet ID (time-based).
- Writes distribute evenly
- Reading one author's tweets requires scatter-gather across partitions
- No hot partition problem
Option C: By author, with hot author sharding.
- Normal authors: single partition
- Celebrities: tweets spread across multiple partitions
- Query complexity increases for celebrities
Tradeoff: Author-partitioned is simple but creates hotspots. Tweet-partitioned distributes load but complicates author queries. Hybrid adds complexity.
Design choice 3: How many replicas, and what consistency?
Option A: Strong consistency. Write waits for all replicas.
- No stale reads
- Write latency increases
- Availability decreases (any replica down blocks writes)
Option B: Eventual consistency. Write to primary, replicate asynchronously.
- Fast writes
- Stale reads possible
- Under pressure, replication lag grows
Tradeoff: Strong consistency privileges readers (no stale data), taxes write latency and availability. Eventual consistency privileges write speed, taxes read freshness.
Design synthesis for Tweet Storage:
- Acknowledge after write to primary plus at least one replica. Balance between durability and speed.
- Partition by author for normal users. Shard hot authors across multiple partitions with consistent routing.
- Eventual consistency for timeline reads. Accept brief staleness. Timeline is already eventually consistent by nature—fan-out takes time regardless.
- Separate write path (must be durable) from read path (can serve from replicas). Optimize each independently.
Follow Graph Service
The problem: Know who follows whom. Answer two queries: "who follows X?" (for fan-out-on-write) and "who does Y follow?" (for fan-out-on-read).
Simplest design: Store edges in database. User A follows User B = row (A, B). Query by follower or followee.
Where wrongness accumulates:
Between follow action and graph update. User clicks follow. How long until the graph reflects this?
Between graph update and timeline impact. Graph is updated. Fan-out or assembly hasn't seen the change yet.
In asymmetric query costs. "Who does A follow?" might return 500 results. "Who follows celebrity X?" might return 50 million results.
Design choice 1: How do we store the graph?
Option A: Single edge table. Query by either column.
- Simple
- Either "followers of X" or "following of X" is indexed; other requires scan
- Both queries cannot be optimal
Option B: Dual storage. Maintain both (follower → followee) and (followee → follower) indexes.
- Both queries are efficient
- Write amplification: every follow is two writes
- Consistency risk between the two stores
Tradeoff: Single store is simple but one query direction is slow. Dual store is fast for reads but doubles writes and risks inconsistency.
Design choice 2: How do we handle celebrity follower lists?
"Who follows @taylorswift?" returns 90 million edges. This cannot be returned in a single query.
Option A: Paginate. Return followers in chunks.
- Works for any size
- Fan-out-on-write must iterate through all pages
- Slow for massive lists
Option B: Pre-segment. Store celebrity followers in sharded segments. Fan-out can parallelize across segments.
- Faster fan-out for celebrities
- More complex storage model
- Must decide who is a "celebrity"
Option C: Don't answer this query for celebrities. Celebrities use fan-out-on-read; follower list is never enumerated.
- Sidesteps the problem
- Requires hybrid fan-out architecture
- Must still answer "who does Y follow?" for celebrity followers
Tradeoff: Pagination is simple but slow for huge lists. Pre-segmentation is faster but complex. Avoiding the query requires architectural changes elsewhere.
Design choice 3: How quickly must follow changes propagate?
Option A: Synchronous. Follow is not acknowledged until graph is updated and downstream systems notified.
- User sees immediate effect
- Slow acknowledgment
- Coupling to downstream systems
Option B: Asynchronous. Acknowledge follow immediately, propagate in background.
- Fast acknowledgment
- User may not see immediate effect
- Propagation lag is invisible to user
Tradeoff: Synchronous privileges user expectation (I followed, I should see their tweets), taxes latency. Asynchronous privileges speed, taxes consistency of experience.
Design synthesis for Follow Graph Service:
- Dual storage for both query directions. Accept write amplification for read efficiency.
- Asynchronous propagation. Acknowledge follow immediately, update graph asynchronously.
- Pre-segment followers for accounts above threshold (say, 100K followers). Enable parallel fan-out.
- Cache hot graphs. Most timeline requests come from active users following similar popular accounts. Cache "who does X follow?" for active users.
- Publish follow/unfollow events. Let downstream systems (fan-out, timeline cache) subscribe and update their state.
Fan-out System
The problem: When a tweet is posted, get it into followers' timelines. This is where the core architectural decision lives.
Option 1: Fan-out-on-write (push model)
When tweet is posted:
- Query "who follows this author?"
- For each follower, write tweet reference to their timeline cache
Characteristics:
- Work is proportional to follower count
- Write amplification: 1 tweet → N writes (N = follower count)
- Read is simple: fetch pre-assembled timeline
- Celebrity problem: 50M followers = 50M writes per tweet
Option 2: Fan-out-on-read (pull model)
When timeline is requested:
- Query "who does this reader follow?"
- For each followed account, fetch recent tweets
- Merge and rank
Characteristics:
- Work is proportional to following count
- Read amplification: 1 timeline request → N queries (N = following count)
- Write is simple: just store the tweet
- Heavy reader problem: user following 5,000 accounts = expensive assembly
Option 3: Hybrid
Fan-out-on-write for normal users. Fan-out-on-read for celebrities.
Characteristics:
- Avoids worst cases of both
- Complexity: must classify users, handle edge cases
- Timeline assembly must merge cached (fanned-out) and fetched (on-demand) tweets
Where wrongness accumulates in each model:
Fan-out-on-write:
Fan-out lag. Tweet posted at T0. Fan-out completes at T0 + 30 seconds. Followers requesting timeline between T0 and T0+30 don't see the tweet.
Wrongness is invisible to readers. They don't know a tweet was posted that they haven't received. They see a timeline that looks complete but isn't.
Under pressure, fan-out lag grows. Readers see increasingly stale timelines without knowing it.
Fan-out-on-read:
Assembly latency. Reader requests timeline. Assembly takes 2 seconds under pressure. Reader waits.
Wrongness is visible to readers. They see the spinner. They know something is slow.
Under pressure, readers may give up. But they know the system is struggling.
Hybrid:
Merge complexity. Some tweets came from fan-out cache. Some from on-demand fetch. Merging must produce coherent timeline.
Edge cases. User follows 500 normal accounts (fanned out) and 10 celebrities (fetched on demand). Timeline must merge both sources correctly.
Threshold artifacts. Account at 99K followers is fanned out. Account at 101K is not. Similar accounts, different behavior. If threshold changes, accounts shift categories, timeline behavior changes.
Design choice 1: Where is the threshold for hybrid?
Option A: Fixed follower count (e.g., 100K followers).
- Simple rule
- Arbitrary cutoff
- Accounts near threshold may oscillate as followers fluctuate
Option B: Dynamic based on system load.
- Under pressure, lower the threshold—more accounts become "celebrities," reducing fan-out load
- Complex to implement
- Behavior is unpredictable to users
Option C: Based on posting frequency × follower count.
- High-frequency celebrities (news accounts) pulled
- Low-frequency celebrities (actors who tweet rarely) can be fanned out
- More nuanced but more complex
Tradeoff: Fixed is simple but arbitrary. Dynamic adapts but is unpredictable. Frequency-adjusted is smarter but harder to implement and explain.
Design choice 2: How do we handle fan-out lag?
When fan-out is behind, readers see stale timelines. What do we do?
Option A: Nothing. Accept staleness.
- Simple
- Readers don't know they're missing tweets
- Under pressure, experience degrades silently
Option B: Show "new tweets available" indicator when fan-out catches up.
- Reader knows to refresh
- Requires tracking what reader has seen vs what's available
- Additional complexity
Option C: Supplement cached timeline with on-demand fetch for very recent tweets.
- Always check author's last few tweets, even for fanned-out accounts
- Reduces staleness at cost of additional reads
- Hybrid becomes more complex
Tradeoff: Silent staleness is simple but degrades trust. Indicators are honest but add complexity. Supplemental fetch reduces staleness but increases read load.
Design choice 3: Fan-out ordering and priorities
Celebrity tweets should reach engaged followers quickly. But 50M followers can't all be first.
Option A: Random order. All followers equally likely to receive tweet early or late.
- Fair
- Engaged users (who check frequently) may receive tweet after they've already checked
Option B: Prioritize active users. Fans who check frequently get fan-out first.
- Active users see fresh content
- Inactive users receive tweet eventually
- Requires tracking activity levels
Option C: Geographic/time-based. Fan out to users in waking hours first.
- Tweets arrive when people are likely to see them
- Complex to implement
- May feel unfair to night owls
Tradeoff: Random is fair but not optimized. Activity-based is smart but requires tracking and may feel unfair. Geographic is contextual but complex.
Design synthesis for Fan-out System:
- Hybrid model. Fan-out-on-write below threshold (100K followers). Fan-out-on-read above.
- Fixed threshold for simplicity. Accept the edge case artifacts.
- Prioritize fan-out to active users. Use recent login time as proxy for activity.
- "New tweets available" indicator when fan-out catches up to reader's position. Be honest about staleness.
- Under extreme pressure, raise threshold temporarily. More accounts become pull-based, reducing fan-out load. Revert when pressure subsides.
Timeline Cache
The problem: Store pre-assembled timelines for fast reads (in fan-out-on-write model). Or cache assembled results (in fan-out-on-read model).
Simplest design: Per-user list of tweet IDs, ordered by time. Bounded size (e.g., last 800 tweets). Fetch and return on request.
Where wrongness accumulates:
Cache staleness. Fan-out hasn't reached this user yet. Cache returns stale timeline.
Cache size limits. User follows many active accounts. Cache can only hold 800 tweets. Older tweets are evicted. User scrolls back, hits the boundary, experiences discontinuity.
Cache cold start. New user, or user returning after long absence. No cached timeline. Must assemble from scratch.
Design choice 1: What do we cache?
Option A: Full tweet content.
- Fast reads—no additional fetch needed
- Cache size explodes (tweets with media, etc.)
- Tweet edits/deletes require cache invalidation
Option B: Tweet IDs only.
- Small cache footprint
- Read requires hydration—fetch full tweet content by IDs
- Tweet edits/deletes don't require cache invalidation
Tradeoff: Full content is fast but large and stale-prone. IDs only are compact but require hydration step.
Design choice 2: How do we handle cache misses?
Option A: Assemble on demand. Cache miss triggers full timeline assembly.
- Eventually consistent
- Cold start is slow
- Under pressure, cache misses amplify load
Option B: Serve partial results. Return what's cached, assemble rest asynchronously.
- Fast response
- User sees incomplete timeline initially
- Must handle "more tweets loading" UX
Option C: Pre-warm caches. Predict who will request timeline, assemble before they ask.
- Fast reads for predicted users
- Wasted work for unpredicted users
- Must predict accurately
Tradeoff: On-demand assembly is correct but slow on miss. Partial results are fast but incomplete. Pre-warming is fast but speculative.
Design choice 3: How long do cached timelines live?
Option A: Indefinitely, updated by fan-out.
- Always current (as current as fan-out)
- Memory pressure from inactive users
- Stale data for users who stopped receiving fan-out
Option B: TTL-based expiration.
- Bounded memory
- Cache miss after TTL
- Active users may experience unnecessary misses
Option C: LRU eviction.
- Memory bounded
- Active users stay cached
- Inactive users evicted, cold start on return
Tradeoff: Indefinite is current but unbounded. TTL is bounded but arbitrary. LRU is adaptive but inactive users pay cold start cost.
Design synthesis for Timeline Cache:
- Cache tweet IDs, not full content. Hydrate on read. Accept hydration latency for compactness and avoiding invalidation complexity.
- LRU eviction. Active users stay warm. Inactive users evicted, accept cold start cost on return.
- Partial results on cold start. Return top tweets quickly, backfill asynchronously. "Loading more tweets" is better than spinner.
- Bound cache size per user (800-1000 tweets). Scrolling beyond cache hits persistent storage. Different latency expectation is acceptable for deep scrolling.
Timeline Assembly Service
The problem: For fan-out-on-read accounts (celebrities) and cold starts, assemble timeline from source data.
Simplest design: Query followed accounts, fetch recent tweets from each, merge by timestamp, return.
Where wrongness accumulates:
Query fan-out. User follows 500 accounts. Even with batching, this is significant query load.
Merge complexity. 500 accounts × 10 recent tweets each = 5,000 tweets to merge. Must sort, dedupe (retweets), apply ranking.
Latency accumulation. Each step adds latency. Under pressure, latency compounds beyond acceptable bounds.
Design choice 1: How do we query followed accounts' tweets?
Option A: Sequential queries.
- Simple
- Latency is sum of all queries
- Unacceptable for large following counts
Option B: Parallel queries with scatter-gather.
- Latency is max of queries, not sum
- Requires managing many concurrent connections
- Partial failures must be handled
Option C: Pre-aggregated feeds for popular accounts.
- Celebrity accounts have pre-built recent tweet lists
- Reduces scatter-gather for most common follows
- Additional storage and maintenance
Tradeoff: Sequential is simple but slow. Parallel is fast but complex. Pre-aggregation optimizes common case but adds infrastructure.
Design choice 2: What if some queries fail or timeout?
Option A: Fail entire assembly.
- Consistent—either complete timeline or nothing
- One slow account blocks everything
- Poor experience under partial failure
Option B: Return partial results, exclude failed sources.
- User sees something quickly
- Some followed accounts' tweets missing
- Must communicate incompleteness
Option C: Return cached stale results for failed sources.
- User sees complete-looking timeline
- Some content may be stale
- Staleness is invisible
Tradeoff: Failing entirely is consistent but fragile. Partial results are honest but incomplete. Stale fallback is complete but potentially misleading.
Design choice 3: How do we bound assembly latency?
Option A: Hard timeout. Return whatever is assembled when timeout hits.
- Bounded latency
- Potentially incomplete results
- Predictable user experience
Option B: Adaptive. Adjust parallelism and depth based on system load.
- Optimizes for conditions
- Unpredictable latency
- Complex tuning
Tradeoff: Hard timeout is predictable but may be incomplete. Adaptive optimizes but is unpredictable.
Design synthesis for Timeline Assembly:
- Parallel scatter-gather. Query all followed accounts concurrently.
- Pre-aggregate recent tweets for high-follow accounts. Most users follow some popular accounts; optimize for this.
- Hard timeout (e.g., 500ms). Return what's assembled. Incomplete is acceptable; slow is not.
- Stale fallback for failed queries. If a source fails, use last known tweets from that source. Prefer complete-looking stale over incomplete fresh.
- Progressive loading. Return top results fast, continue assembling for scroll depth.
Ranking Service
The problem: Given candidate tweets, order them by relevance to the reader. Chronological is simple but not engaging. Algorithmic increases engagement but creates expectations mismatch.
Simplest design: Sort by timestamp, newest first.
Where wrongness accumulates:
Chronological wrongness: user misses important tweets because they were buried by volume. User follows 1,000 accounts, checks once a day. They see only what was posted in the last hour.
Algorithmic wrongness: user sees tweets out of order, feels manipulated. "Why am I seeing a tweet from yesterday above one from an hour ago?"
Expectation mismatch: user doesn't know which mode they're in. They assume chronological, see algorithmic, feel confused.
Design choice 1: Chronological vs algorithmic?
Option A: Pure chronological.
- Predictable
- Users understand what they're seeing
- High-volume follows bury low-volume quality
- Miss important tweets from infrequent posters
Option B: Pure algorithmic.
- Optimizes for engagement
- Users don't understand ordering
- Filter bubble concerns
- "Why am I seeing this?" frustration
Option C: User choice.
- Users can switch modes
- Must maintain both pipelines
- Default matters—most won't change it
Tradeoff: Chronological is honest but suboptimal for engagement. Algorithmic is engaging but opaque. Choice is flexible but complex.
Design choice 2: If algorithmic, what signals?
- Recency (when was it posted?)
- Author relationship (how often do you interact with this author?)
- Engagement (how many likes/retweets?)
- Content type (photo, video, text?)
- Topic relevance (does it match your interests?)
Each signal adds compute. Each signal can be gamed. Each signal has failure modes.
Tradeoff: More signals = better ranking but more compute and more gaming surface. Fewer signals = simpler but less personalized.
Design choice 3: How do we handle ranking latency under pressure?
Option A: Skip ranking, return chronological.
- Fast fallback
- Experience changes under load
- Users notice inconsistency
Option B: Use simplified ranking model.
- Faster than full model
- Less optimal ranking
- Consistent experience type
Option C: Cache ranked results.
- Fast reads for repeat requests
- Stale ranking
- Doesn't adapt to new tweets between requests
Tradeoff: Falling back to chronological is honest but inconsistent. Simplified ranking is consistent but lower quality. Caching is fast but stale.
Design synthesis for Ranking Service:
- Default to algorithmic with chronological option. Let users choose, default to engagement-optimized.
- Limit signals to computable set. Recency, author interaction history, engagement. Avoid expensive content analysis in hot path.
- Simplified model as fallback. Under pressure, use faster model with fewer signals rather than falling back to chronological.
- Cache ranking inputs, not outputs. Cache author interaction scores, not ranked timelines. Ranking can still adapt to new tweets.
- Be transparent about what "For You" vs "Following" means. Different tabs, clear labels.
Engagement/Analytics
The problem: Count impressions, likes, retweets, replies. Provide accurate metrics to authors and advertisers.
Type: Dependent. Evaluates after the fact.
Simplest design: Log every impression. Aggregate in batch. Serve counts from aggregated data.
Where wrongness accumulates:
Real-time vs accurate. Counting 1M impressions per second with perfect accuracy is hard. Systems approximate in real-time and reconcile in batch.
Definition ambiguity. What's an impression? Tweet rendered on screen? Tweet scrolled past? Tweet visible for 1 second? Different definitions, different counts.
Under pressure, logging degrades. Events dropped. Counts are undercounted. Authors see lower engagement than actual.
Design choice 1: Real-time counts vs batch-only?
Option A: Real-time counters, increment on every event.
- Authors see immediate feedback
- Distributed counting is hard
- Under pressure, counters may lose events
Option B: Batch only. Counts update hourly/daily.
- Accurate
- Slow feedback loop
- Authors frustrated by stale counts
Option C: Approximate real-time, accurate batch.
- Best of both
- Two systems, must reconcile
- Visible jumps when batch corrects real-time
Tradeoff: Real-time is fast but potentially inaccurate. Batch is accurate but slow. Both is comprehensive but creates visible reconciliation artifacts.
Design choice 2: How do we handle undercounting during pressure?
Option A: Accept it. Counts are lower bounds.
- Simple
- Authors see suppressed engagement
- May lose ad revenue if impressions undercounted
Option B: Estimate and adjust. Use sampling to extrapolate.
- Better accuracy under pressure
- Statistical complexity
- Estimates may be wrong
Option C: Buffer and replay. Queue events during pressure, process when recovered.
- Eventually accurate
- Requires durable queue
- Batch reconciliation is delayed
Tradeoff: Accepting undercounts is simple but loses accuracy. Estimation is smart but adds uncertainty. Buffering is accurate but delays reconciliation.
Design choice 3: What's an impression?
Option A: Tweet fetched for timeline.
- Easy to measure (server-side)
- Overcounts—tweet may not render, user may not scroll to it
Option B: Tweet rendered on client.
- More accurate
- Requires client reporting
- Client may not report (offline, closed app)
Option C: Tweet visible for N seconds.
- Most meaningful for attention
- Complex to measure
- High reporting load
Tradeoff: Server-side overcounts but is reliable. Client-rendered is more accurate but lossy. Visibility-based is meaningful but expensive.
Design synthesis for Engagement/Analytics:
- Approximate real-time with batch reconciliation. Show fast estimates, correct with accurate batch counts.
- Buffer events during pressure. Accept delayed reconciliation over permanent undercount.
- Server-side for impressions, client-side for engagement (likes, retweets). Impressions can overcount; engagement must be accurate.
- Clear definitions for advertisers. Document what "impression" means. Don't change definitions without notice.
Ads Service
The problem: Insert promoted tweets into timelines. Target accurately. Bill correctly.
Type: Dependent on impression/engagement data. Also injects into timeline assembly.
Where wrongness accumulates:
Between targeting and delivery. Ad targeted to user. User's interests changed. Ad is now irrelevant.
Between delivery and billing. Ad shown but impression not logged. Or impression logged but ad not actually shown (cache, bug, etc.).
Between advertiser expectation and reality. Advertiser expected 1M impressions. Got 800K. Why? Targeting too narrow? System under pressure? Competition for ad slots?
Design choice 1: When do we select ads?
Option A: At timeline assembly time.
- Fresh targeting
- Adds latency to timeline
- Under pressure, ad selection may be skipped
Option B: Pre-selected ad pool, insert at assembly.
- Fast insertion
- Targeting may be stale
- Pool must be refreshed periodically
Tradeoff: Real-time selection is accurate but slow. Pre-selection is fast but potentially stale.
Design choice 2: What if ad selection fails/times out?
Option A: Show no ad.
- Timeline loads quickly
- Lost revenue
- Inconsistent ad load
Option B: Show fallback ad (less targeted).
- Revenue preserved
- Lower relevance
- User experience may suffer
Option C: Show house ad (promote Twitter features).
- Slot filled, no lost external revenue
- Not monetized
- Acceptable degradation
Tradeoff: No ad prioritizes user experience but loses revenue. Fallback preserves revenue but may be irrelevant. House ad is compromise.
Design choice 3: How do we ensure billing accuracy?
Impression logged at timeline assembly. But did user see it?
Option A: Bill on server impression.
- Simple
- May overbill
- Advertiser distrust
Option B: Bill on client-confirmed visibility.
- More accurate
- Client may not report
- Underbilling
Option C: Bill on server, refund on discrepancy.
- Conservative for advertiser
- Complex reconciliation
- Good faith relationship
Tradeoff: Server billing is simple but overcounts. Client billing is accurate but undercounts. Refund model is fair but complex.
Design synthesis for Ads Service:
- Pre-selected ad pool per user segment, refreshed frequently. Balance freshness and latency.
- Fallback to less-targeted ads under pressure. Preserve revenue over perfect targeting.
- Bill on server impression, audit with client visibility. Provide transparency to advertisers.
- Separate ad delivery metrics from organic metrics. Different SLAs, different pipelines.
Operations/Monitoring
The problem: See system health. Detect degradation. Intervene effectively.
Type: Supervisor
Simplest design: Aggregate metrics (timeline latency, fan-out lag, cache hit rates). Alert on thresholds. Dashboard for humans.
Where wrongness hides:
Aggregate masks local. Global timeline latency is 200ms. Timeline latency for users following many celebrities is 2s.
Fan-out lag is invisible to readers. Readers don't know they're missing tweets. Metrics show fan-out queue depth, not reader experience of staleness.
Engagement drops may be system issue or content issue. Hard to distinguish "system dropping events" from "users aren't engaging with this content."
Design choice 1: What metrics matter most?
Option A: System metrics. Latency, error rate, queue depth.
- Easy to measure
- Doesn't capture user experience
- System can look healthy while users suffer
Option B: Experience metrics. Time-to-first-tweet, staleness, completeness.
- Captures what users feel
- Harder to measure
- Requires end-to-end instrumentation
Tradeoff: System metrics are easy but indirect. Experience metrics are meaningful but harder to instrument.
Design choice 2: How do we detect fan-out staleness?
Option A: Monitor queue depth and lag.
- Measures system state
- Doesn't show which users are affected
Option B: Sample reader timelines, compare to expected.
- Measures actual staleness
- Expensive (requires timeline assembly for comparison)
- Sampling may miss localized problems
Tradeoff: Queue metrics are cheap but indirect. Sampling is accurate but expensive.
Design choice 3: What interventions are available?
When timeline latency spikes, options include:
- Raise celebrity threshold (more accounts use fan-out-on-read → less fan-out load)
- Skip ranking (faster assembly)
- Serve stale cache more aggressively
- Reject some percentage of requests (backpressure)
Each intervention routes wrongness somewhere. Must understand where.
Design synthesis for Operations/Monitoring:
- Both system and experience metrics. Queue depth AND time-to-first-tweet. Error rate AND completeness.
- Sample timeline freshness. Periodically check "when was newest tweet posted" vs "when was it visible to follower."
- Tiered interventions with documented wrongness tradeoffs. Write runbook: "If fan-out lag > 60s, raise celebrity threshold. Effect: more users experience assembly latency instead of staleness."
- Expose "system is degraded" to users when appropriate. Honest degradation beats silent wrongness.
Twitter Timeline — Summary of Design Tradeoffs
| System | Primary Tradeoff | Who Gains | Who Pays |
|---|---|---|---|
| Tweet Storage | Acknowledge after durable write vs async | Author certainty vs speed | Authors pay with latency or durability |
| Follow Graph | Dual storage vs single | Read speed vs write simplicity | Writes pay for read efficiency |
| Fan-out | Write vs read | Read latency vs write amplification | Celebrities break fan-out-on-write; heavy readers break fan-out-on-read |
| Fan-out | Fixed vs dynamic threshold | Simplicity vs adaptability | Edge cases pay for simplicity |
| Timeline Cache | IDs vs full content | Size/freshness vs read latency | Hydration latency pays for compactness |
| Assembly | Complete vs partial results | Consistency vs latency | Completeness pays for speed |
| Ranking | Chronological vs algorithmic | Predictability vs engagement | User understanding pays for engagement |
| Analytics | Real-time vs batch | Feedback speed vs accuracy | Accuracy pays for immediacy |
| Ads | Real-time vs pre-selected | Targeting accuracy vs latency | Targeting pays for speed |
| Operations | System vs experience metrics | Ease vs accuracy | Understanding pays for measurement simplicity |
The Twitter timeline problem is fundamentally about where to put work: write time (fan-out-on-write) or read time (fan-out-on-read). Neither eliminates work. Both route pressure differently.
The celebrity problem forces hybrid. The hybrid forces complexity at the merge point. Under pressure, any choice degrades—the question is which degradation readers can tolerate.