Design Discussions: Jira Migrations
I recently came across an interesting post on the Atlassian blog about “Scaling Jira Cloud migrations with external importers.” I like…
I recently came across an interesting post on the Atlassian blog about “Scaling Jira Cloud migrations with external importers.” I like delving into design — especially of systems that run at medium to high scale — so this post is an attempt to discuss the architecture Atlassian describes, highlight potential design issues, and explore an alternate concept centric approach that might make the solution more extensible and future-proof.
Disclaimer
I’m not affiliated with Atlassian, nor do I have inside knowledge of their internal systems. The analysis that follows is based solely on the public blog post and my experience designing large-scale software.
All opinions expressed here are my own; they don’t represent the views of Atlassian or any current employer or client. They are based on my understanding of the system, derived from what has been presented in the original post. It can have gaping holes.
Any architectural critique inevitably omits context that only the original authors possess. Treat this discussion as a springboard for deeper thinking, not as a definitive judgment.
Quick recap of what the article claims
- Legacy CSV importer sat inside the Jira monolith; it capped out at ~6000 issues / hr, required full-platform scaling and saw only 70–80 % success for big jobs .
- A four-phase rewrite is presented:
- micro-service CSV importer driven by an AWS-Step-Functions “Migration Process Orchestrator”
- direct API-based importers for Trello, Asana, etc.
- Async attachment pipeline to keep file transfers off the critical path
- a “no-code” framework where mappings live in a Configuration Store and engineers ship new importers largely by authoring YAML/JSON rules .
Atlassian reports ×20 throughput, ×30 data-rate and 95 % success after the overhaul.
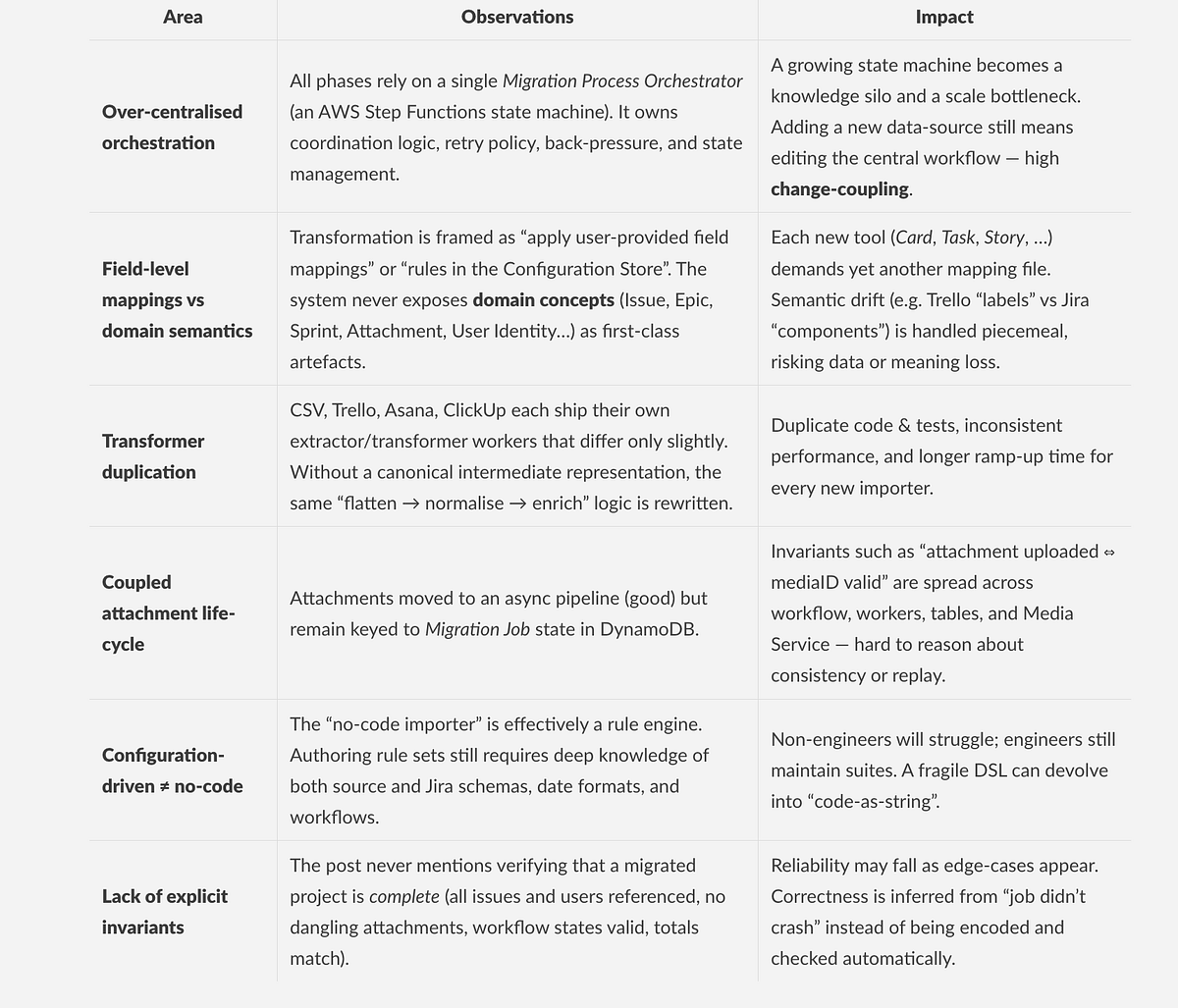
Architectural and design critique
A Possible Alternative Design
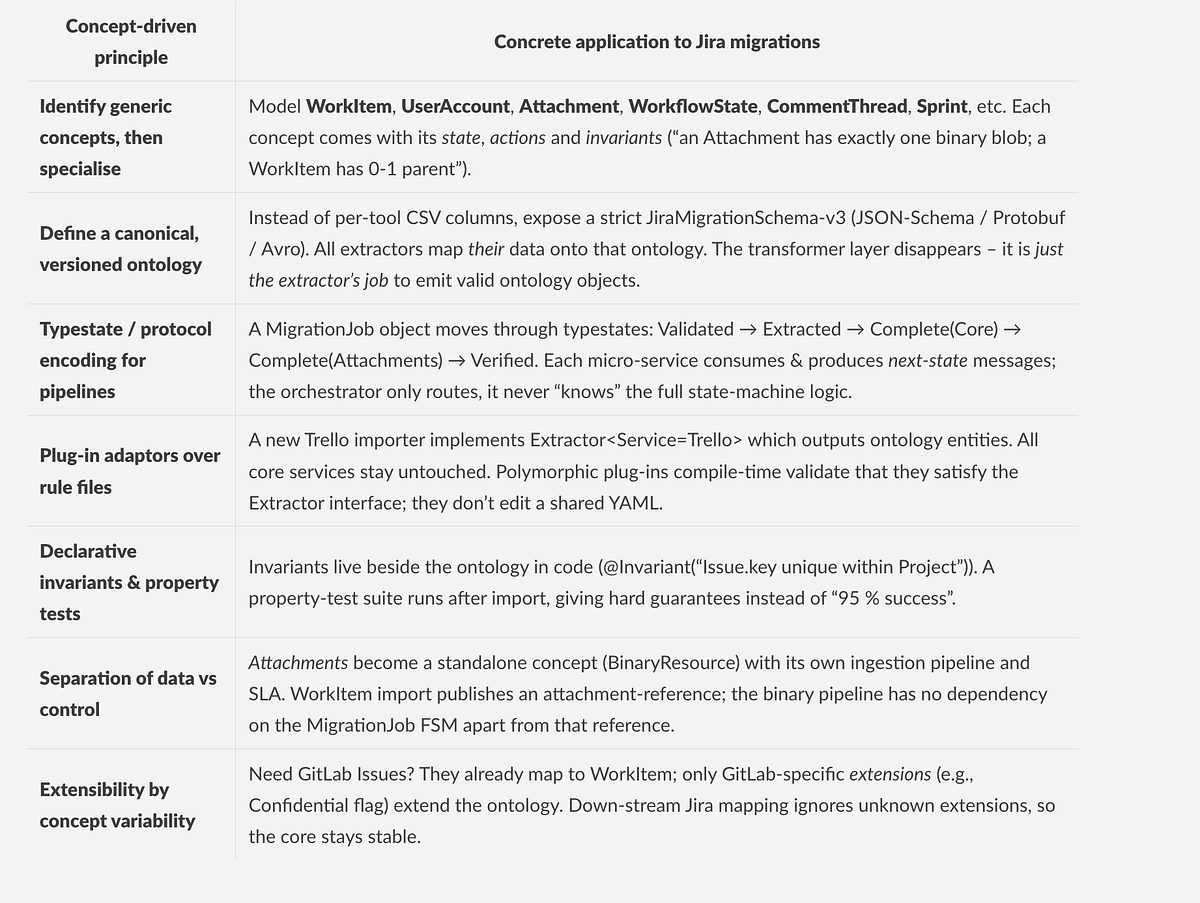
Benefits realised
- O(1) change-surface: adding a new tool means adding one extractor class. No orchestrator edits, no rule-file sprawl.
- Scalable reasoning: each service upholds invariants on a tiny slice of the ontology; global correctness is the product of local proofs.
- Polyglot & future-proof: want a streaming import instead of batch? Implement a streaming extractor; ontology and core remain the same.
- Automated verification & roll-back: failed invariants surface instantly, attachments can replay independently, rollback is concept-scoped not job-scoped.
Potential next steps
- Draft the canonical ontology for migration now, before more “no-code” rules accrete.
- Convert existing extractors to emit ontology objects rather than raw maps/JSON.
- Refactor the orchestrator into a thin event router; move business rules into per-concept processors that advance typestate and publish events.
- Introduce a property-based verification pass that runs after each phase and before customer cut-over — attach it to SLIs, not just logs.
- Replace fragile field-mapping DSLs with typed adaptor plug-ins — written once per tool, compiled, versioned, and tested like any other code.
Adopting a concept-centric design does not negate the micro-services or AWS primitives that delivered the performance gains; it simply layers a stable, explicit semantic model on top, giving the same scalability for evolution that they have already achieved for throughput.