Designing Retries Without Taking Down Your System
Designing Retries Without Taking Down Your System

Retries form a geometric series. If p is your failure rate, each failed request spawns another attempt that also fails with probability p. The total load on the system is:
Total Load = 1 + p + p² + p³ + ...Two cases matter.
Unbounded retries — retry until success. The geometric series converges to:
1 / (1 - p)This is the theoretical ceiling — the maximum load your retries can generate.

Bounded retries — cap at n attempts. You compute 1 + p + p² + ... + pⁿ:
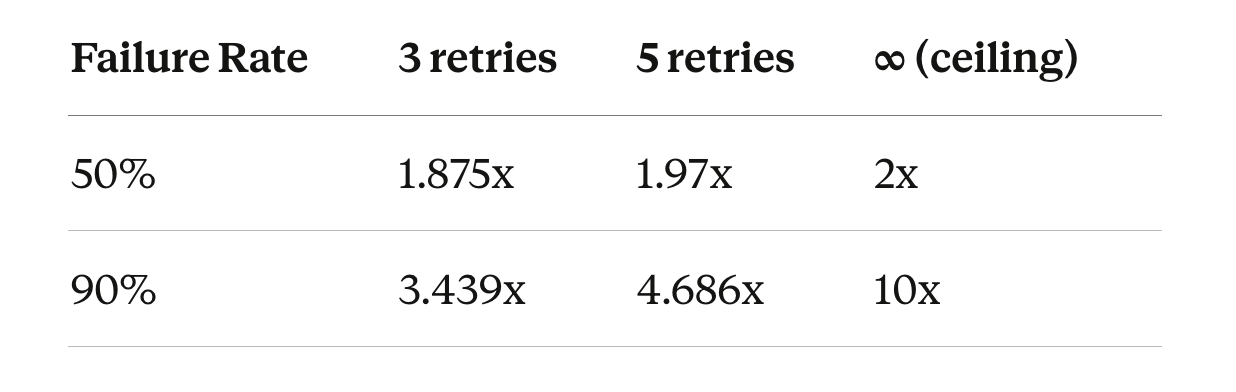
3.4x is what you pay today with 3 retries at 90% failure. 10x is the ceiling you’re asymptotically moving toward as retries increase. Each additional retry adds more load but barely improves success — at 90% failure, going from 3 to 5 retries costs 1.2x more traffic for a few percent more successes. You spend more and more traffic for smaller and smaller gains.
The load multiplier is hyperbolic in the failure rate, not linear. Going from 50% to 90% failure doesn’t double retry load — it quintuples it.
The right question isn’t “how many retries?” It’s “how much extra load can I afford during failure?”
Define your constraint: say your system tolerates 1.3x load under stress. Now use the formula.
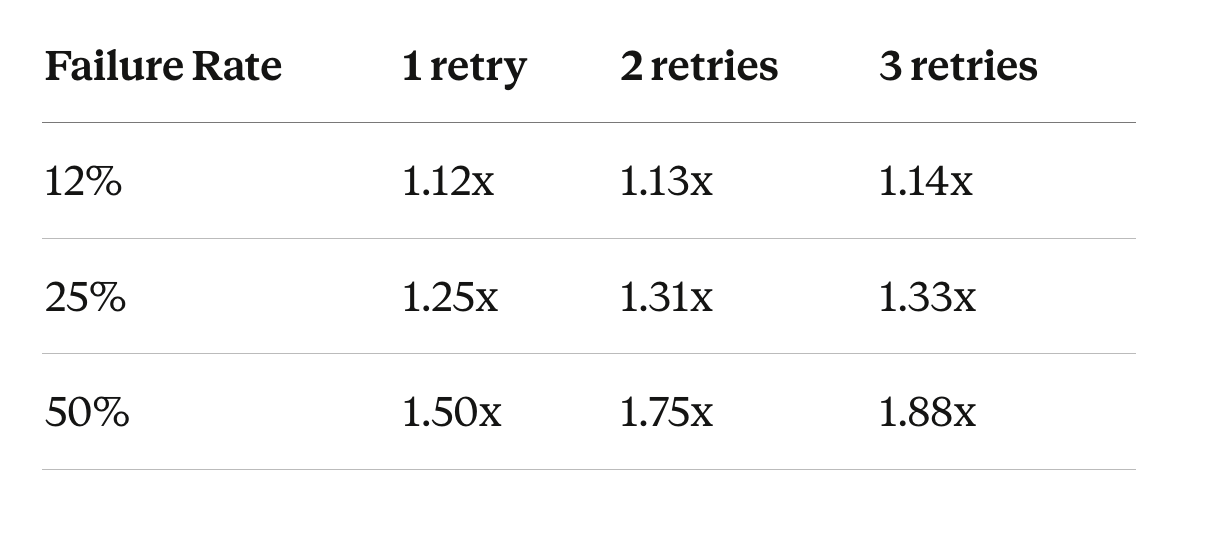
At 12% failure, 3 retries costs 1.14x — well within budget. At 25%, 2 retries already hits 1.31x — borderline. 3 retries blows past it. At 50%, even 1 retry exceeds your 1.3x budget. The failure rate determines how many retries you can afford, not the other way around.
Now add feedback. Retries increase load. Load increases failure rate. Higher failure rate increases retries. A 2x traffic spike pushes failure to 30%. Retries multiply load by 1.43x — upstream sees 2.86x. It slows. Failure climbs to 60%. Retries multiply by 2.5x — upstream sees 5x. The spike passes, but the upstream can’t recover because retry traffic sustains the overload.
Retries are a load amplification mechanism, not a reliability feature. Used precisely — at low error rates where the geometric series barely grows — they smooth transient failures. Used blindly, they turn partial failure into system collapse.
The geometric series is what makes three mechanisms structurally necessary:
Retry budgets bound the series directly. Instead of fixed retry counts, cap total retry traffic as a percentage of original traffic — say 20%. When error rates rise, retries are dynamically reduced. At 90% failure, instead of 3.4x load you get 1.2x. The series never reaches its ceiling because you’ve truncated it based on what the system can actually absorb.
Circuit breakers sever the feedback loop. The series shows that once p crosses 0.5, retries at minimum double traffic. A circuit breaker detects this threshold and stops sending requests entirely. Retries can no longer increase load, so load can no longer increase failure rate. The half-open state probes recovery without re-triggering the cascade.
Load shedding is the server-side safety valve — it enforces capacity at the edge by rejecting excess traffic early, without trusting clients to behave. Retry budgets and circuit breakers help on the client side, but only load shedding guarantees that overload doesn’t consume critical resources deeper in the system.
These aren’t independent patterns. They’re complementary bounds on the same geometric series. Retry budgets truncate the series based on affordable load. Circuit breakers zero it past a failure threshold. Load shedding caps what the server will accept regardless of what clients do.
Choose retries based on how much extra load you can survive — not how many attempts you want to make.