Cache Locality Beats Big O - What Asymptotic Notation Can't Tell You

Big O notation is a lie of omission.
It tells you how an algorithm scales with input size. It says nothing about the constant factor — the multiplier in front of the n. At scale, that constant factor is dominated entirely by memory access patterns. And memory access patterns are invisible to asymptotic analysis.
An O(1) algorithm with good cache locality will outperform an O(log n) algorithm with poor locality by 10–100x on modern hardware.
The Numbers You Need to Know
Modern CPUs operate at ~0.3ns per cycle. Here’s the actual cost of a memory access depending on where the data lives:
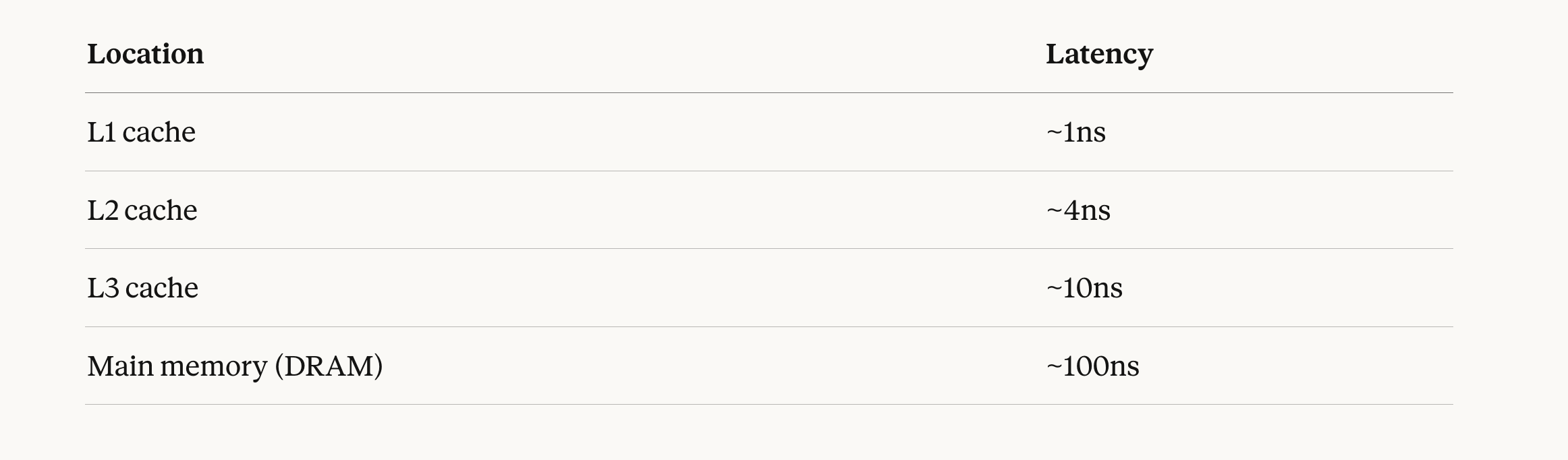
The gap between L1 and DRAM is 100x.
The CPU fetches memory in units of 64-byte cache lines. When you access one byte, the hardware loads the entire 64-byte line containing it. If your next access is in the same line, it’s free. If it’s in a different line, you pay again.
This is the unit of performance that actually matters in practice. Not the operation count. The cache line.
The Min-Heap’s Hidden Cost
A min-heap is a complete binary tree stored in an array. It’s elegant — heap[i]‘s children are at heap[2i] and heap[2i+1]. Insert and extract-min both walk this tree vertically, swapping elements until the heap property is restored.
However vertical traversal is expensive.
At the root, you touch heap[1]. Its children are heap[2] and heap[3] — probably in the same cache line. Their children are heap[4] through heap[7] — likely in the same or adjacent lines. Fine so far.
By level 10, you’re accessing heap[512] through heap[1023]. That’s a contiguous block of ~4KB — still cacheable. But by level 17, you’re accessing indices above heap[65536]. That element is physically nowhere near heap[1]. With 100,000 elements, you have roughly 17 levels, and each level likely lands in a different cache line.
At L3 latency (10ns), 17 pointer chases cost ~170ns per operation. At main memory latency (100ns), it’s 1,700ns.
More importantly: the heap’s working set grows with n. At 256K elements, the working set of a heap exceeds L3 cache. Doubling the element count past this threshold increased runtime by 5x, not 2x. The algorithm didn’t get asymptotically slower — O(log n) barely changes between 256K and 512K. The cache miss rate did. Every heap operation now fetches from main memory. The constant in front of O(log n) jumped by an order of magnitude.
That 5x is the constant factor. Big O has no way to express it.
The Design Principle
Cache locality doesn’t just matter for data structures you build from scratch. It should influence how you organize any data a hot path touches:
- Group fields accessed together. If your request handler reads
request.timeout,request.retries, andrequest.deadlineon every call, put them in the same struct — ideally in the same 64-byte cache line. - Prefer arrays over pointer-linked structures for sequential access. A linked list of 1,000 elements requires 1,000 pointer dereferences, each potentially a cache miss. An array of 1,000 elements with sequential access requires roughly 16 cache line loads.
- Watch your working set. L3 cache on a modern server is 32–64MB. If your hot-path data structure exceeds that, you’re in DRAM territory. Profile with
perf stat -e cache-missesbefore optimizing algorithm complexity. - Let the prefetcher help you. Sequential and stride-based access patterns are predictable. Pointer chasing is not. When you choose between a tree and an array, you’re also choosing between unpredictable and predictable memory access.
Big O tells you the shape of the scaling curve. It doesn’t tell you where the curve sits on the y-axis. At scale, that y-intercept — determined almost entirely by cache behavior — is often the only number that matters.
Design for the cache line first. Optimize for Big O second.